斐波那契堆是具有最小堆序的有根树的集合,也就是集合中的每棵树都具有父结点的关键字小于或等于子结点的关键字。
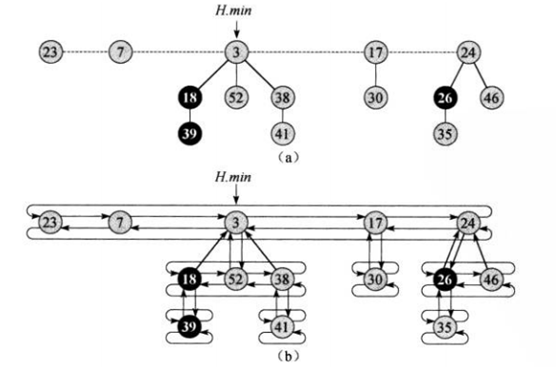
对于每一个结点x,主要有以下属性:
| 名称 | 说明 | 记作 |
|---|---|---|
| 关键字 | 结点存储的值 | x.key |
| 父结点 | 结点的父亲 | x.p |
| 左兄弟 | 结点的左兄弟 | x.left |
| 右兄弟 | 结点的右兄弟 | x.right |
| 孩子 | 结点的一个儿子结点 | x.child |
| 度 | 结点的儿子数量,不包括孙子及下层 | x.degree |
| 标记 | 结点是否有儿子被删除 | x.mark |
堆H本身属性:
| 名称 | 说明 | 记作 |
|---|---|---|
| 最小结点 | 最小的根结点 | H.min |
| 结点数目 | 整个堆中结点的个数 | H.n |
所有树的根结点集合被称为根链表,通过H.min和最小结点的left right值可以构成。
| 操作 | 二项堆(最坏情形) | 斐波那契堆(摊还) |
|---|---|---|
| MAKE-HEAP | O(1) | O(1) |
| INSERT | O(lgn) | O(1) |
| MINIMUM | O(1) | O(1) |
| EXTRACT-MIN | O(lgn) | O(lgn) |
| UNION | O(n) | O(1) |
| DECREASE-KEY | O(lgn) | O(1) |
| DELETE | O(lgn) | O(lgn) |
可以看出,二项堆在插入、合并、修改值操作上摊还时间是常数级别,效率较高。
插入操作
将一个结点x插入到H中,若堆为空则新建一个仅有x的堆,否则将x加入到根链表中
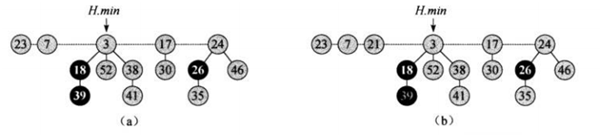
图中所示为21插入到堆中
代码如下:
1 void fibHeapInsert(H,x){
2 x.degree = 0;
3 x.p = NULL;
4 x.child = NULL;
5 x.mark = false;
6 if(H.min == NULL){
7 //新建一个根链表仅含有x
8 H.min = x;
9 }
10 else{
11 //将x插入到H的根链表中
12 if(x.key<H.min.key)
13 H.min = x;
14 H.n++;
15 }
16 }
寻找最小结点
直接通过H.min获得
两个斐波那契堆的合并
直接将两个堆的根链表链接,然后确定新的最小结点
1 fibHeapUnion(H1,H2){
2 H = makeFibHeap();//初始化一个新堆
3 for(p=H1.min;p.right!=NULL;p=p.right);
4 p.right = H2.min;//将H2的根链表链接到H1的根链表右端
5 H.min = (H1.min < H2.min) ? H1.min : H2.min;
6 H.n = H1.n + H2.n;
7 return H;
8 }
抽取最小点
先将最小结点的每个孩子变为根节点,从根链表中删除最小结点,H.min指向最小结点的右兄弟,然后把具有相同度数的结点合并来形成新的根链表,合成过程是迭代的,合成之后结点度数加1,然后再检查有无度数相同结点,直到所有度数的结点在根链表中只有一个。
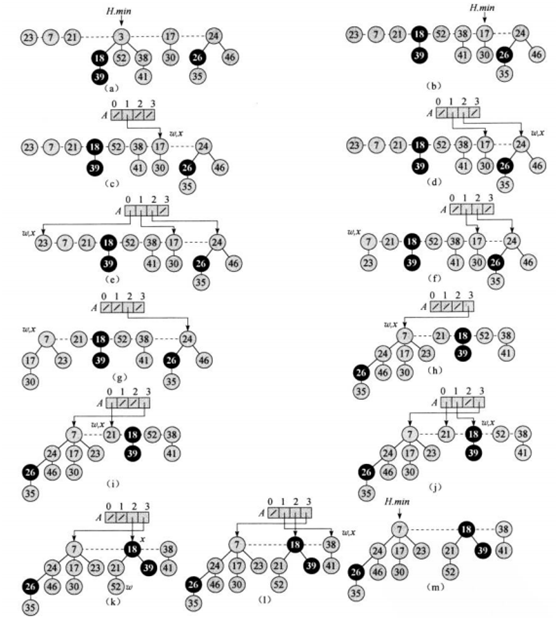
(a)-(b)3的3个儿子都被移到根链接然后3被删除,3的右兄弟17成为H.min。(c)-(d)从17开始遍历根链表,17的度为1,24的度为2,23的度为0,他们都是第一次出现的度值,记录到辅助数组中。(e)7的度也是0,和23重复,且7<23,所以23插入到7的儿子中,7的度变为1。(f)-(g)7的新度值和17重复,17插入到7的儿子中,7的度变为2。(h)7的新度和24重复,24插入到7的儿子中,7的度变为3。(i)-(j)21的度为0,18的度为1,插入到辅助数组。(k)52的度为0,插入到21的儿子中,21的度变为1和18重复,21插入到18的儿子中。
fibHeapExtractMin(H){
z = H.min;
if(z != NULL){
for(x=z.child;x!=NULL;x=x.right){
H.rootList.add(x);
x.p = NULL;
}
H.rootList.remove(z);
if(z==z.right)
H.min = NULL;
else{
H.min = z.right;
consolidate(H);
}
H.n--;
}
return z;
}
consolidate(H){
A[n+1];//用来存储已有度数的辅助数组,n是整个堆中根结点的最大度数
for(i=0;i<=n;i++){
A[i] = NULL;
}
for(w=H.child;w!=NULL;w=w.right){
x=w;
d=x.degree;
while(A[d]!=NULL){//已有度数相同的结点,将该与之前的结点合并
y=A[d];
if(x.key>y.key)
exchange(x,y);//key值大的作为子节点
fibHeapLink(H,y,x);//y插入x的子结点中
A[d]=NULL;
d++;
}
A[d]=x;
}
H.min = NULL;
for(i=0;i<=n;i++){//合并完成后重新构建根链表与最小结点
if(A[i]!=NULL){
if(H.min==NULL){
//创建一个新堆仅有A[i]
H.min = A[i];
}
else{
H.rootList.add(A[i]);
if(A[i].key<H.min.key)
H.min = A[i];
}
}
}
}
fibHeapLink(H,y,x){
H.rootList.remove(y);
for(t=x.child;t.right!=NULL;t=t.right);
t.right = y;
x.degree++;
y,mark=false;
}
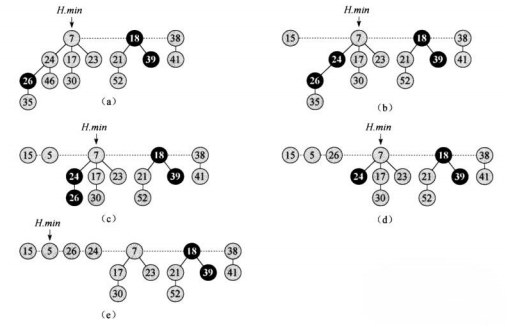
关键字减值
将x结点的key改为k值,若改变后会影响最小堆性质,则将x移动到根链表,并标记父结点,若之前父结点已被标记过,则将父结点也移动到根链表,标记爷结点。递归这个过程直到标记一个未标记过的父结点,这个操作叫做级联删除。最后,若新key值小于原本最小结点值,最小结点变为x。
如图(a)-(b)将46变为15然后15被移到根链表,24被标记。(c)将35改为5,26已经被标记所以(d)中26也被移到根链表。(e)中26的父结点24也被标记过,所以24也移动到根链表,24的父结点7已经在根链表上,该过程终止。
1 fibHeapDecreaseKey(H,x,k){
2 if(k>x.key)
3 return;
4 x.key = k;
5 y = x.p;
6 if(y!=NULLL && x.key < y.key){
7 cut(H,x,y);
8 cascadingCut(H,y);//更改后x.key小于父节点key时,x移动到根链表并对父结点做级联删除
9 }
10 if(x.key<H.min.key)
11 H.min = x;
12 }
13
14 cut(H,x,y){
15 for(t=y.child;t.right!=x;t=t.right);
16 t.right = t.right.right;//从y的child list中移除x
17 y.degree--;
18 for(t=H.min;t.left!=NULL;t=t.left);
19 t.left = x;//将x添加到H的根链表
20 x.p = NULL;
21 x.mark = false;
22 }
23
24 cascadingCut(H,y){
25 z = y.p;
26 if(z!=NULL){
27 if(y.mark==false)
28 y.mark = true;//y未被标记,则标记y
29 else{
30 cut(H,y,z);
31 cascadingCut(H,z);//y已被标记,则将z移到根链表并对y的父结点做级联删除
32 }
33 }
34 }
删除结点
将结点x的值修改为无穷小,然后执行抽取最小值操作