首先强调:Unsafe在JDK9开始被完全禁用了,所以不建议人为使用。
我们知道在多线程环境下,要使用一个线程安全的计数器,大家首先会想到AtomicLong(AtomicInteger),它的核心是利用volatile来修饰value使得对变量的修改对所有线程可见,同时使用Unsafe提供的多种基于底层硬件指令的配合进行compareAndSwap(CAS)操作,达到lock-free的线程安全,提高并发性能。这里的无锁指的是没有重同步锁synchronized,而使用轻量的自旋锁。实际上,在JDK不断对同步锁进行优化之后,如果线程冲突非常频繁,CAS反而不如synchronized,因为自旋实质上没有阻塞线程,长时间自旋是对资源的浪费。
如果要产生自增长序列,那么AtomicLong是非常好的方法,但是如果是一个计数器不需要每次增加都返回当前值,那么LongAdder是一个更好的选择。
volatile
volatile这个关键字的作用有两个:
(1)禁止进行指令重排序
指令重排的例子如下,在不影响执行结果的前提下,编译器会调整语句顺序来对指令码进行优化,isLoad = true这个语句从方法内的角度考虑,放在头部和尾部不影响,但是对于整个程序来说是有问题的,可能线程A修改了状态但还未读取context时,线程B开始初始化而此时context为null,导致抛出异常。如果以volatile来修改变量isLoad,那么isLoad出现的语句都不会被重排,就不会出现这个问题。
public class VolatileTest {
private boolean isLoad = false;
private Object context = null;
private void readContext() {
isLoad = true;//模拟指令重排
System.out.println("正在读取配置");
context = new Object();
//isLoad = true;指令重排前
}
private void initContext() {
if (isLoad) {
System.out.println("正在初始化");
context.toString();
} else {
System.out.println("未读取配置");
}
}
public static void main(String args[]) {
VolatileTest test = new VolatileTest();
Thread t1=new Thread(new Runnable() {
@Override
public void run() {
test.readContext();
}
},"t1");
Thread t2=new Thread(new Runnable() {
@Override
public void run() {
while (true){
if(test.isLoad){
test.initContext();
break;
}
}
}
},"t2");
t1.start();
t2.start();
}
}
(2)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
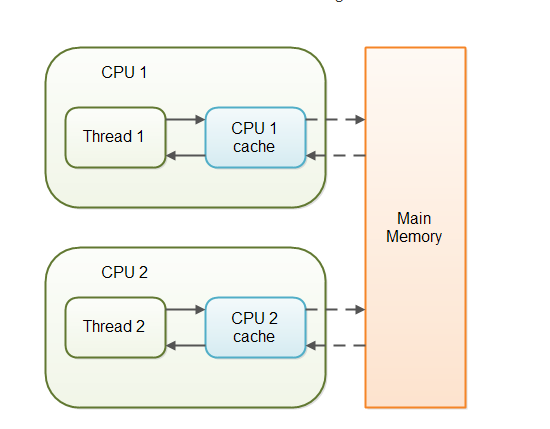
为了提高运行效率,线程在操作主线程的变量时,会将变量的副本拷贝一份到线程的工作区域,避免每次到主线程读取,在更改后的一段时间内写入主内存,所以经常会出现线程不同步的问题。
比如主线程变量a=0,线程A执行一次a++操作,线程B循环判断a==1则执行操作,实际结果可能是这个操作不会开始,因为线程B去主线程取到的副本a=0,在判断时由于a已经存在于线程缓存中不会再去主线程取更新后的a=1,导致条件始终不成立。如果用volatile修饰了变量a,则线程A更新完成后,会将a=1立即复制回主内存,并且删除所有线程缓存中a的副本,线程B发现本地缓存中没有a的值,于是去主从中去a=1,此时条件成立。
但是volatile不能保证原子性。经典案例就是a++问题,即使变量a有volatile修饰,线程A和B分别执行a++,依然有可能输出1和2。原因是a=a+1获取a变量时它可能是0也可能是1。
AtomicLong
因为AtomicLong里面很多方法都是基于Unsafe提供的JNI方法,所以下面对于方法的分析会直接带入分析。从OpenJDK里面可以找到jdk/src/share/classes/sun/misc/Unsafe.java,和hotspot/src/share/vm/prims/unsafe.cpp,以及文末贴出的libjava版本。
先列一下AtomicLong里面用到的Unsafe方法,实际上这里的Long也有Object或者Integer版本:
- compareAndSwapLong
- getAndAddLong
- getAndSetLong
- putOrderedLong
构造函数与内部变量与静态块
可以看到在类加载时,需要获取Unsafe的实例,检查JVM是否支持无锁的long型CAS操作,获取类中value字段的偏移量。构造函数可以指定初始值也可以默认为0。value值用volatile变量修饰。
private static final long serialVersionUID = 1927816293512124184L;
// setup to use Unsafe.compareAndSwapLong for updates
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
/**
* 记录下层JVM是否支持无锁的long型CAS操作。当Unsafe.compareAndSwapLong在某个情况下工作,
* 一些构造器需要在Java层面处理来避免锁住用于可见的锁。
*/
static final boolean VM_SUPPORTS_LONG_CAS = VMSupportsCS8();
/**
* 返回下层JVM是否支持无锁的long型CAS操作。只调用一次并缓存在VM_SUPPORTS_LONG_CAS。
*/
private static native boolean VMSupportsCS8();
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicLong.class.getDeclaredField("value"));//获取类中value字段的位置
} catch (Exception ex) { throw new Error(ex); }
}
private volatile long value;
/**
* 创建一个AtomicLong指定初始值
*/
public AtomicLong(long initialValue) {
value = initialValue;
}
/**
* 创建一个AtomicLong初始值为0
*/
public AtomicLong() {
}
get与set
get与set是直接获取与更新value值
public final long get() {
return value;
}
public final void set(long newValue) {
value = newValue;
}
而getAndSet原子性设定为给出值并且返回旧值
public final long getAndSet(long newValue) {
return unsafe.getAndSetLong(this, valueOffset, newValue);
}
/**
* 原子性地将指定对象和偏移量位置的字段或数组元素的当前值替换为指定值并返回旧值
*
* @param o object/array to update the field/element in
* @param offset field/element offset
* @param newValue new value
* @return the previous value
* @since 1.8
*/
public final long getAndSetLong(Object o, long offset, long newValue) {
long v;
do {
v = getLongVolatile(o, offset);
} while (!compareAndSwapLong(o, offset, v, newValue));//自旋重复尝试更新值
return v;
}
/**
* 如果当前值是expected,原子性地更新为x,成功的话返回true
*/
public final native boolean compareAndSwapLong(Object o, long offset,
long expected,
long x);
public native long getLongVolatile(Object o, long offset);
先看compareAndSwap这个方法的实现,给出OpenJDK和libjava两种版本。libjava应当是对应不使用CPU指令的这种情况。
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapLong(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jlong e, jlong x))
UnsafeWrapper("Unsafe_CompareAndSwapLong");
Handle p (THREAD, JNIHandles::resolve(obj));
jlong* addr = (jlong*)(index_oop_from_field_offset_long(p(), offset));
if (VM_Version::supports_cx8())//如果底层支持,直接使用CPU指令
return (jlong)(Atomic::cmpxchg(x, addr, e)) == e;//CPU指令LOCK CMPXCHG
else {//不支持则依靠JVM实现
jboolean success = false;
ObjectLocker ol(p, THREAD);
if (*addr == e) { *addr = x; success = true; }
return success;
}
UNSAFE_END
// Use a spinlock for multi-word accesses
class spinlock
{
static volatile obj_addr_t lock;
public:
spinlock ()
{
while (! compare_and_swap (&lock, 0, 1))
_Jv_ThreadYield ();//有线程占用锁则yield当前线程
}
~spinlock ()
{
release_set (&lock, 0);//析构时释放锁
}
};
static inline bool
compareAndSwap (volatile jint *addr, jint old, jint new_val)
{
jboolean result = false;//操作是否成功
spinlock lock;//自旋锁竞争操作权限
if ((result = (*addr == old)))//如果当前值为old,result=true
*addr = new_val;//更新值
return result;
}
getLongVolatile也根据硬件是否支持原子性IRIW即读即写操作分为两种
#define GET_FIELD_VOLATILE(obj, offset, type_name, v) \
oop p = JNIHandles::resolve(obj); \
if (support_IRIW_for_not_multiple_copy_atomic_cpu) { \
OrderAccess::fence(); \
} \
volatile type_name v = OrderAccess::load_acquire((volatile type_name*)index_oop_from_field_offset_long(p, offset));
UNSAFE_ENTRY(jlong, Unsafe_GetLongVolatile(JNIEnv *env, jobject unsafe, jobject obj, jlong offset))
UnsafeWrapper("Unsafe_GetLongVolatile");
{
if (VM_Version::supports_cx8()) {
GET_FIELD_VOLATILE(obj, offset, jlong, v);//直接通过指令读取
return v;
}
else {
Handle p (THREAD, JNIHandles::resolve(obj));
jlong* addr = (jlong*)(index_oop_from_field_offset_long(p(), offset));
ObjectLocker ol(p, THREAD);//自旋
jlong value = *addr;//从内存获取值
return value;
}
}
UNSAFE_END
jlong
sun::misc::Unsafe::getLongVolatile (jobject obj, jlong offset)
{
volatile jlong *addr = (jlong *) ((char *) obj + offset);
spinlock lock;
return *addr;
}
另一个方法compareAndSet如果当前value==expect,则原子性的更新value为update,返回是否操作成功,同样借助了unsafe.compareAndSwapLong。但前面方法是强制更新,这个要比较预期值。
public final boolean compareAndSet(long expect, long update) {
return unsafe.compareAndSwapLong(this, valueOffset, expect, update);
}
lazySet
lazySet是使用Unsafe.putOrderedObject方法,这个方法在对低延迟代码是很有用的,它能够实现非堵塞的写入,这些写入不会被Java的JIT重新排序指令(instruction reordering),这样它使用快速的存储-存储(store-store) barrier, 而不是较慢的存储-加载(store-load) barrier, 后者总是用在volatile的写操作上,这种性能提升是有代价的,写后结果并不会立即被其他线程甚至是自己的线程看到,通常是几纳秒后被其他线程看到,这个时间比较短,所以代价可以忍受。
public final void lazySet(long newValue) {
unsafe.putOrderedLong(this, valueOffset, newValue);
}
/** Ordered/Lazy version of {@link #putLongVolatile(Object, long, long)} */
public native void putOrderedLong(Object o, long offset, long x);
下面是native方法的实现,因为OpenJDK版本异常复杂,可以看下面libjava版本的。关于spinlock lock这段,个人理解是自旋等待其他线程结束占用,然后修改内存中value的值。相比直接修改value,延后了删除其他线程中的缓存这一步。
#define SET_FIELD_VOLATILE(obj, offset, type_name, x) \
oop p = JNIHandles::resolve(obj); \
OrderAccess::release_store_fence((volatile type_name*)index_oop_from_field_offset_long(p, offset), x);
UNSAFE_ENTRY(void, Unsafe_SetOrderedLong(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jlong x))
UnsafeWrapper("Unsafe_SetOrderedLong");
#ifdef SUPPORTS_NATIVE_CX8
SET_FIELD_VOLATILE(obj, offset, jlong, x);
#else
// Keep old code for platforms which may not have atomic long (8 bytes) instructions
{
if (VM_Version::supports_cx8()) {
SET_FIELD_VOLATILE(obj, offset, jlong, x);//指令设置
}
else {
Handle p (THREAD, JNIHandles::resolve(obj));
jlong* addr = (jlong*)(index_oop_from_field_offset_long(p(), offset));
ObjectLocker ol(p, THREAD);
*addr = x;
}
}
#endif
UNSAFE_END
void
sun::misc::Unsafe::putOrderedLong (jobject obj, jlong offset, jlong value)
{
volatile jlong *addr = (jlong *) ((char *) obj + offset);//计算value字段地址
spinlock lock;//自旋
*addr = value;//设置值
}
getAndAdd和addAndGet
下面几个方法本质上都是一个意思,原子性的增减当前值,返回新值或者旧值。全部都是基于Unsafe.getAndAddLong,实现方法是循环尝试compareAndSwapLong,如果因为有其他线程更新而失败则getLongVolatile重新获取当前值。
/**
* 原子性的将当前值增加1,返回旧值
*/
public final long getAndIncrement() {
return unsafe.getAndAddLong(this, valueOffset, 1L);
}
/**
* 原子性的将当前值减少1,返回旧值
*/
public final long getAndDecrement() {
return unsafe.getAndAddLong(this, valueOffset, -1L);
}
/**
* 原子性的将当前值增加delta,返回旧值
*/
public final long getAndAdd(long delta) {
return unsafe.getAndAddLong(this, valueOffset, delta);
}
/**
* 原子性的将当前值减少delta,返回旧值
*/
public final long incrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L;
}
/**
* 原子性的将当前值减少delta,返回新值
*/
public final long decrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, -1L) - 1L;
}
/**
* 原子性的将当前值增加delta,返回新值
*/
public final long addAndGet(long delta) {
return unsafe.getAndAddLong(this, valueOffset, delta) + delta;
}
//Unsafe.getAndAddLong原子性的增加delta到字段或者数组元素的当前值,返回旧值
public final long getAndAddLong(Object o, long offset, long delta) {
long v;
do {
v = getLongVolatile(o, offset);
} while (!compareAndSwapLong(o, offset, v, v + delta));
return v;
}
下面这段引自桐人姥爷的公众号文章:特别留意到 Jdk1.7 中 unsafe 使用的方法是 compareAndSwapLong,它与 x86 CPU 上的 LOCK CMPXCHG 指令对应,并且在应用层使用 while(true) 完成自旋,这个细节在 Jdk1.8 中发生了变化。Jdk1.7 的 CAS 操作已经不复存在了,转而使用了 getAndAddLong 方法,它与 x86 CPU 上的 LOCK XADD 指令对应,以原子方式返回当前值并递增(fetch and add)。
public final long getAndIncrement() {//JDK1.7
while (true) {
long current = get();
long next = current + 1;
if (compareAndSet(current, next))
return current;
}
}
public final boolean compareAndSet(long expect, long update) {
return unsafe.compareAndSwapLong(this, valueOffset, expect, update);
}
但是,从我上面对源码的分析,似乎跟上段有出入,依然是基于循环compareAndSwapLong来实现。为此,我特地求证了公众号原文作者,他的回复是:JDK版本的差异,高版本的JDK8确实是已经修改了unsafe.getAndAddLong的底层实现。
LongAdder
前面提到AtomicLong在线程碰撞不频繁时效率较高,但是如果线程碰撞频繁,长时间的自旋会浪费大量资源。对于一个计数器来说,绝大部分情况下并不关心当前值是多少,只要少量按需get即可。所以,引入了LongAdder。
LongAdder在JDK1.8新增加,继承的是Striped64,这个类是Number的子类,用于表示64位的动态条带。 Striped64内部含有一个cells数组,用于存储线程使用的计数器。并且Striped64在构造时是不会初始化数组的。Cell是一个线程间共享的计数器。
/**
* AtomicLong的填补变体,只支持通过CAS访问
* JVM内联函数注意事项:如果提供了的话可能只使用一个release-only的CAS版本
*/
@sun.misc.Contended static final class Cell {
volatile long value;//内部实际值
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);//通过compareAndSwapLong替换value值从cmp为val
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}
/** CPU的数量用来设置表大小的范围 */
static final int NCPU = Runtime.getRuntime().availableProcessors();
/**
* 存储格表。非null时大小是2的指数
*/
transient volatile Cell[] cells;
/**
* 基础值,主要用于没有竞争的时候,但也作为表舒适化竞争时的返回值。通过CAS更新。
*/
transient volatile long base;
/**
* 在resize和创建cells时使用的自旋锁(用CAS加锁)
*/
transient volatile int cellsBusy;
结合来看LongAdder的add方法,因为Striped64构造时cells是null,会先尝试CAS修改base值,cells初始化后一般不会使用base,仅在做resize操作期间有可能。前一步都失败了,则尝试从cells数组中获取当前线程对应的cell并通过CAS修改。cell未初始化或者修改没能成功,则进入Striped64.longAccumulate。注意,cell的选择是根据ThreadLocalRandom产生的随机数选择的。
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {//优先使用cells,cells未初始化时尝试cas修改base
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))//尝试cas修改线程对应的cell
longAccumulate(x, null, uncontended);//产生冲突时尝试在cells中新增cell
}
}
/**
* CAS修改base值
*/
final boolean casBase(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, BASE, cmp, val);
}
/**
* 返回当前线程的探针值。从ThreadLocalRandom复制,因为有包限制,它们两个不在同一个包中。
*/
static final int getProbe() {
return UNSAFE.getInt(Thread.currentThread(), PROBE);
}
来看一这个方法longAccumulate,代码比较长。大致上进行的顺序是:
- cells没有初始化则先竞争锁然后进行初始化
- 已有cells表则检查有无剩余空间,不足时竞争锁后进行resize扩容,但最大不能超过CPU总数,因为同一时间不可能有超过CPU总数的线程在运行。
- 表空间足够则竞争锁后新建一个Cell实例,并加入表中后返回
- 如果需要初始化或者resize时,会尝试CAS修改base
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization强制初始化
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty上一个位置非空时为true
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {
if ((a = as[(n - 1) & h]) == null) {//最后一个位置为null
if (cellsBusy == 0) { // Try to attach new Cell尝试关联新的cell
Cell r = new Cell(x); // Optimistically create乐观创建
if (cellsBusy == 0 && casCellsBusy()) {//竞争锁
boolean created = false;
try { // Recheck under lock在锁下再次检查
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;//新建成功
}
} finally {
cellsBusy = 0;//释放锁
}
if (created)
break;
continue; // Slot is now non-empty这个位置现在不是空的
}
}
collide = false;
}
else if (!wasUncontended) // CAS already known to fail已知CAS失败
wasUncontended = true; // Continue after rehash rehash后继续
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;//尝试cas更新cell的value值
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale到达了最大大小或者过时了
else if (!collide)
collide = true;
else if (cellsBusy == 0 && casCellsBusy()) {//竞争锁
try {
if (cells == as) { // Expand table unless stale表没过时的话扩展它
Cell[] rs = new Cell[n << 1];//大小乘以2
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;//释放锁
}
collide = false;
continue; // Retry with expanded table用扩展后的表重试
}
h = advanceProbe(h);
}
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table初始化表
if (cells == as) {
Cell[] rs = new Cell[2];//表初始大小为2
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))//在初始化和resize过程中会进入这个判断
break; // Fall back on using base使用base返回
}
}
increment和decrement都是基于add完成的。不做赘述。
sum返回当前总数。返回值不是一个原子快照。在没有进行并发更新时调用获取的是准确值,但是在计算总数时进行并发更新可能不会包括当前增加值。sum的过程是取当前的base和cells,计算它们的总和。这种惰性求值的思想,在 ConcurrentHashMap 中的 size() 中也存在。因此LongAdder高效之处就在于,它让不同线程同时去操作不同的计数器,避免线程碰撞而长时间自旋。然后采用惰性求和的方式返回一个不完全准确的当前值,对于网站访问计数器这样的场景非常合适
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}